large-Scale Tv Dataset
French Sign Language
(STVD-LSF)
LSF (French Sign Language) is a natural language expressed through hand movements and facial expressions. It shares the same linguistic properties as spoken French. LSF is part of the family of sign languages used worldwide by deaf and hard-of-hearing individuals, such as ASL (American Sign Language) and LSB (Belgian Sign Language).
Sign language recognition is a well-established research topic in computer vision with contributions for multiple languages, including Chinese, Arabic, Vietnamese, English, and French. When a video containing sign language sequences is paired with a speech translation, the task becomes a multimodal recognition problem, involving the integration of audio, textual, and visual data.
The STVD-LSF dataset has been developed to enable scalable multimodal LSF recognition. It comprises several test sets featuring high-resolution videos, multiple interpreters, and a wide range of topics. Each test set is accompanied by corresponding audio speech translations and transcriptions.

Currently, STVD-LSF is available in a β version, which includes a Hello World test set. It provides approximately 7.5 hours of LSF video content, involving 15 interpreters and recorded at standard video quality. In this setup, recognition must be performed from scratch
using only the provided video data. A more comprehensive version is planned for future release, expected to include several tens of hours of high-quality audiovisual material.
The dataset is structured as follows:
-
a
SEGMENTSdirectory containing all LSF video segments encoded in MPEG-4, - an index file in a CSV format.
The dataset has the naming convention described here:
/ |
SEGMENTS |
/ |
FileName.mp4 |
| / | index.csv |
where,
-
FileNameis an LSF video segment named according to the templateCX_Day_video_N_t0-t1, -
CXis a channel identifier, whereX ∈ ℕ+. Each identifier corresponds to a specificChannel(e.g.,C0={France2}), -
videois a text label, -
Day,t0andt1represent timestamps.Dayfollows the template |YEAR|MONTH|DAY| (e.g., 20220618).t0andt1follow the template |HOURS|MINUTES|SECOND| (e.g., 140113), indicating the start and end times of the segment, -
Nis the segment index associated with a given channelCXandDay, -
the
indexis provided as a CSV file with the following structure
FileName;CX;Channel;Day;start;t0;t1;D;dx;dy;Interpreter
whereFileName,CX,Channel,Day,t0,t1are defined as above,startindicates the recording start time (actual segment times are computed asstart+t0,start+t1),Dis the duration of the LSF video segment (in minutes),dx,dyrepresent the dimensions of the video (i.e., the extracted region of interest, RoI),Interpreteris the identifier of the person appearing in the LSF segment.
For understanding purposes, samples of LSF video segments are provided in the following table.
| Int | Segment 1 | Segment 2 | Segment 3 |
| 1 | int1_seg1 | int1_seg2 | int1_seg3 |
| 2 | int2_seg1 | int2_seg2 | int2_seg3 |
| 3 | int3_seg1 | int3_seg2 | int3_seg3 |
| 4 | int4_seg1 | int4_seg2 | int4_seg3 |
| 5 | int5_seg1 | int5_seg2 | int5_seg3 |
The dataset is available for non-commercial research purposes only.
To access the dataset, users must first download the agreement
(available in English or French ),
complete and sign it, and then send a scanned copy by email
to Mathieu Delalandre ![]() .
After reviewing and validating the request, we will provide the password required to extract the dataset.
.
After reviewing and validating the request, we will provide the password required to extract the dataset.
The dataset can be downloaded from the table below, which also presents general statistics. The hosting service at UT typically provides download speeds ranging from 3 MB/s to 16 MB/s, depending on network conditions and concurrent usage. Consequently, the dataset can generally be downloaded within a few minutes.
| Period | Channel | Duration (h) | Segments | Resolution | Encoding (Mb/s) | FPS | Interpreter | Size (GB) | Link |
| Jun-Jul 2022 | 1 | 7.5 | 58 | 240×384 |
[0.57;1] |
29.97 | 15 | 2.42 | download |
For clarity, we detail here technical and scientific aspects of the STVD-LSF dataset.
-
Root videos: were captured according to the methodology described in [1].
The video streams were encoded on the workstation at bitrates ranging from
[1.60;1.62]Mb/s in SD resolution (720×576), to achieve a trade-off between visual quality and storage cost. RoI were extracted at a fixed size240×384, corresponding to≈ ⅕of the original resolution, with output bitrates between[0.57;1]Mb/s. The encoding process was performed in real-time without latency, maintaining a constant frame rate of≈30FPS. -
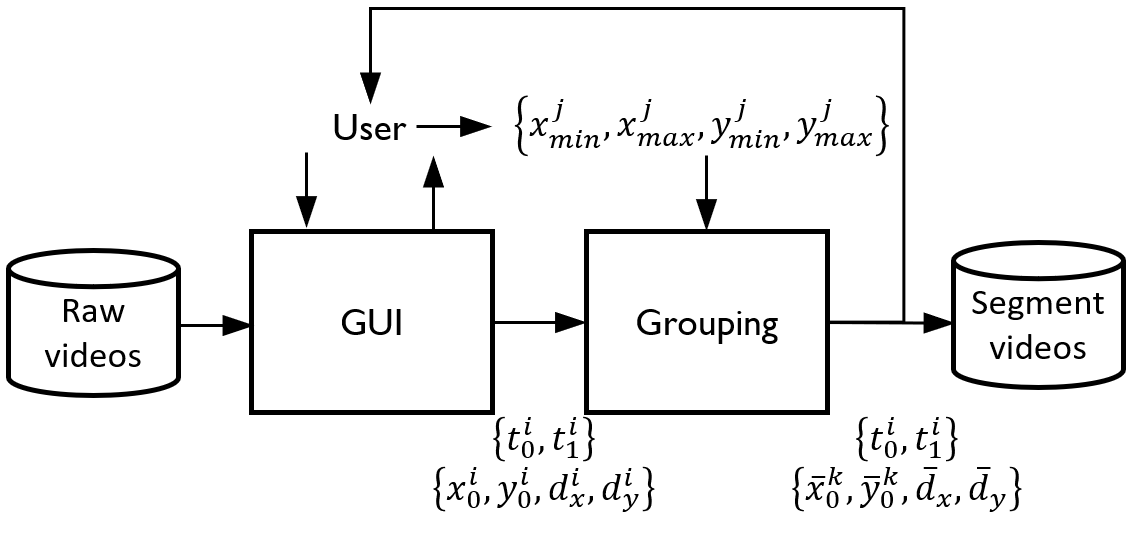
RoI videos: the pipeline used to extract the RoI is described below.
Using a a graphical user interface (GUI), an expert user selects a set of segments from raw videos. Each segment
iis defined by a start and a end timestamp{t0,t1}and bounding box coordinates{x0,yo,dx,do}. The user then defines expert grouping rulesj, where{xmin,xmax,ymin,ymax}specify bounds on thex0andyocoordinates. An additional rule is applied to thedxanddyvalues. The grouped coordinates are processed to obtain median valuesx0andy0, having an indexk. The value ofdxanddyare computed using the same process, followed by a rounding operation:r(dx/2q)×2qandr(dy/2q)×2q. The parameterqis chosen so thatr(dx/2q-1)×r(dy/2q-1)<642andr(dx/2q)×r(dy/2q)>642. The median values (x0,y0) are then adjusted using a margin error, for examplex0−εwhereε=r((r(dx/2q)×2q−dx)/2)(and similarly fory0). The overall process follows an iterative, loop-based methodology in which the user corrects outliers{x0,y0,dx,dy}and refine the timestamps{t0,t1}.
- F. Rayar, M. Delalandre and V.H. Le. A large-scale TV video and metadata database for French political content analysis and fact-checking. Conference on Content-Based Multimedia Indexing (CBMI), pp. 181-185, 2022.